

Data Streaming ▶ Event Sourcing
From Data Streaming to Event Sourcing

Build a strong foundational understanding for data streaming—opposed to batch processing—by reading the book Designing Data Intensive Applications (DDIA). This post is part of a series inspired by that book. The previous CTT issue looked into data streaming. Today we are exploring it in the context of events.

This is going to be a difficult topic. Not because it is hard to understand. Rather, because we will be using words that are so context-sensitive that we can mix them up easily. Event this, event that. Log, stream, record. Database. To make this somewhat easier, I invite you to suspend your disbelief for a moment.
Join me in adopting a simplified vocabulary for the duration of this article:
events, facts…: Without any context, plural—immutable facts about the past. “This has happened.”
Event Record: A representation of an event, usually in JSON or binary form, capturing a specific, singular event. Usually created from a producer and captured by a consumer into a stream.
Event Message: Contextual to Message Brokers—this is the form of an event record that is captured by a Message Queue. It may be deleted, or saved on disk, in this context we don’t consider that detail.
Event: Capital E, no context—I will always use this form when talking about Event Sourcing and Event Modeling Events Records (!)
Event Stream: A named stream, grouping together facts. Without context, this may refer to a stream of incoming event records or messages. In an Event Sourcing context, I will refer to it as such by stating it’s as a Sourced Stream, Event Source or Event Store 🤯
Event Log: A stream of event records that was saved to disk (even if they are deleted afterwards).
Whew, okay… still with me?
Small Design Up Front
Coaching teams in these systems I found it fairly unreasonable to do it in a strictly agile fashion. Chaos, exploration and constant refactoring don’t lend themselves well to an immutable data structure.
But rather than Big Design Up Front—good ol‘ waterfall—your team can follow a leaner approach to designing the Data stream process: with Event Modeling.
Event Logs persisted to disk are notoriously tempting to be treated as NoSQL, no schema, wild west cowboy data stores. However, some level of consistency is likely going to be mandatory if the system is complex.
A good strategy is to treat the data schema to the same level of immutability as the log itself: append-only. By versioning the schema and making sure all changes are backward-compatible, you ensure a level of consistence that should make your releases durable.
When Does Streaming become Sourcing?
Traditionally Applications with OLTP focus on fast, concurrent writes by multiple users. To accomplish that one would use a SQL or SQL-adjacent database. When querying this database, the application creates derivative data and DTOs. The database contains tables and views full of data. The data represent a point-in-time snapshot.
This snapshot is considered to be the canonical source of truth for that family of data. The master–record. It was created by aggregating all event records of changes up until this point. An event record of change in an SQL database would be INSERT, UPDATE, DELETE statements, etc.; including schema changes.
Those of you that dealt with database replications will recognise similar patterns with Write-Ahead Logs (WAL) and Change Data Capture (CDC). WAL and CDC attempt to recreate or temporarily preserve this about-to-be-thrown away data.
The point-in-time state comes with an inherent drawback: we discard all the records of changes. Data is being thrown away.
Event sourcing is simply the decision not to throw these Events away. Instead, they are stored in an Event Log inside an Event Store. The events in this store can be contextually replayed—they have an implicit order, and when recorded on a single store that order can be used to replay to any point-in-time state. We call these replays Projections.
All possible Projections can be derived from the Event Store, thus making the a point-in-time snapshot unnecessary. The Events in the store become the canonical source.
Why Event Modeling?
We no longer have a default point-in-time state to read from. Projections need to be created first. They need to be defined. Event Modeling is nothing more but a process that captures the visual documentation of how, why and when projections are updated.
This process lends itself very well to understanding the flow of data not just its persisted schema. This is very helpful to add much-needed business understanding and data engineering practices into modern software engineering.
This overlaps very well with Event Storming from DDD and Team Topologies.
Difference between Event Storming and Event Modelling

Event Storming If you followed any content about the Strategic side of DDD you no doubt stumbled upon Event Storming. Simply put it’s an exchange of understanding of the underlying domain. Engineers seek to understand how the business side sees and explains what’s going on with processes, data, type…
Aren’t we keeping a lot of data?
The book DDIA also highlights the point about disk space issues. Whether it’s for an Event Log-backed Message Queue or an Event Store, the data will slowly add up. After all, it’s an append-only log!
“If you only ever append to the log, you will eventually run out of disk space.”
–Designing Data Intensive Applications
That doesn’t mean we cannot delete—or rather move data. You can partition data in an OLTP database or archive some old, unused data. This helps compartmentalise the data storage servers into hot and cold storage. Understanding the equivalent of this process is what sets apart event sourcing beginners from experts: tombstoning.
But first, let’s look at the creation-side. There is an upcoming issue in this series on how to manage disk space. Stay tuned!
Is CDC Equivalent to Event Sourcing?
In short, no. Change Data Capture is great for replicating a database, allowing us to setup a destination that is different from the source. The differences may be in read vs. write optimisations, minor schema changes, partitioning.
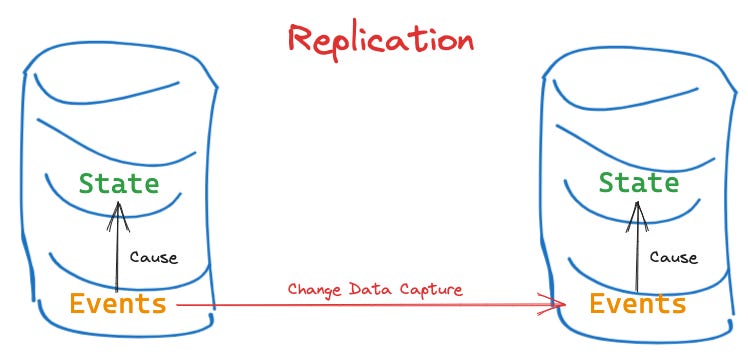
But ultimately, CDC only gives us part of the picture. Notably, the Events Records it provides through the CDC Stream are anemic—specific to the Database Technology of the source, rather than the Business Domain of the originated user action. This is a crucial piece of the puzzle.
However, there are many modern strategies to enrich these CDC records with some contextualised data that we won’t go into further detail in this series. I recommend you check out design strategies using Kafka and Debezium for further inspection.
Leadership
An immediate drawback to this approach is node leadership. I purposely noted the Event Store in the drawing below to be a “Faux” store. Can you spot why that is? Consider the idea of leadership and replication. Which database controls the master record? Which node is the leader that all derivate data is being replicated from to keep in sync with.
Exactly.
Unless the original store on the left is scheduled to be sunset, it will remain a problem from an Event Sourcing standpoint—the event store cannot become the leader unless the original database relinquishes its control over the derived STATE.
However, it can still continue to produce events. I’m sure that by now you’re getting the picture of how a migration strategy using CQRS may become useful here—and indeed that’s how most architects think about this transition in absence of a pure event sourced system.
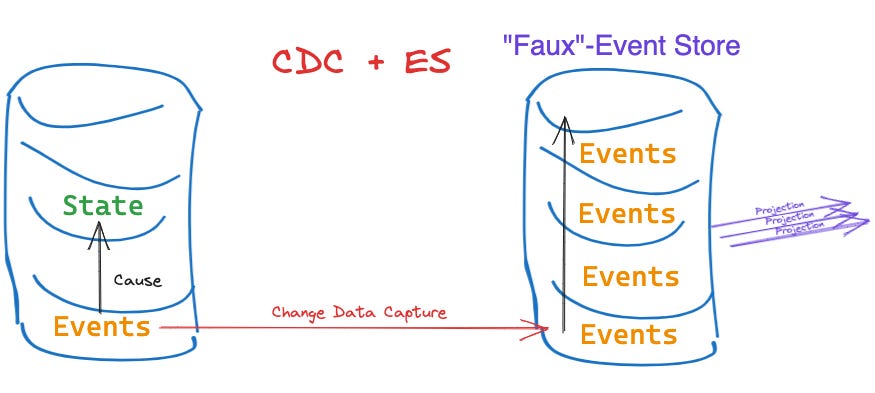
The main criticism by event sourcing opponents is getting stuck in this transitional CQRS state with a CDC cluster and an old database. You don’t need CDC. And you certainly don’t need CQRS. But as you established it is an easy trap to fall into. Clinging to the old database at all costs and transition in (too-)small steps will prevent you from making the hard changes.
Just like with any refactoring of this magnitude—the intermediate complexity increases drastically before it reduces in the pure event sourced state:
This is part of a series on Event Sourcing and Modeling while reviewing the book Designing Data-Intensive Applications by Martin Kleppmann.
Learn something new? Share it.