


Today’s Crafting Tech Teams Issue is about Tactical Domain-driven Design Patterns. We will explore a common problem with Aggregates: when to use them—what to model them around and how what conversations to facilitate in order to discover them.
I will use two scenarios to depict this from two levels of analysis–a technical one with a unique constraint and a business with race conditions. I’m confident this will highlight the strengths and weaknesses of this design approach.
TLDR picture at the bottom next to the Share and Subscribe buttons. Thanks!

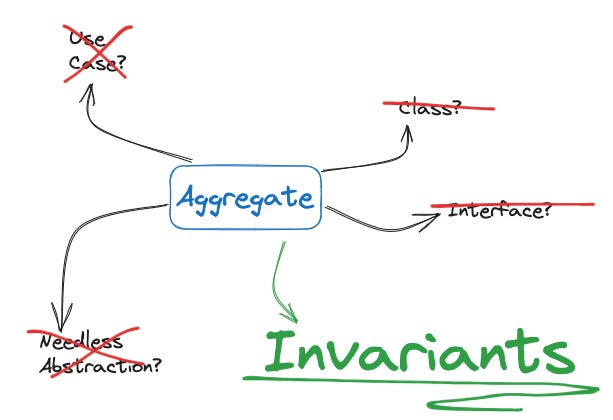
What is an Invariant?
“In computer science, an invariant is a logical assertion that is always held to be true during a certain phase of execution of a computer program.”
Okay, in plain English please? I’m sure you have heard the phrase business logic and business rules come up in various software talks. Especially talks featuring Domain-driven Design. Invariants are the process of enforcement for those business rules.
Invariants come in many forms. Let’s call them rules for now. There are legal rules, there are security rules.
There are rules that apply in one context but not in others. There are physical rules, the rules of nature.
Specifically for our case this CTT issue, we care about rules that apply within and adjacent to a cluster of objects. Here are things to look for:
Groups of objects that have to change together (transactions)
Groups of objects that have to rollback together (compensation, sagas, transactions)
Uniques—one of something
Limits—X number of something
Sorting order other than absolute time
Keep in mind what we care about is invariants that are local. As you’ll see in the example below a global invariant that spans the entire organisational dataset is not appropriate for an aggregate.
Example: Unique Emails for login
This one is easy to spot. Perhaps not so easy to model.
Scenario 1
Alice registers on the website. Uses her email. Wants to login with her email.
She goes through the quick registration flow and uses her email to log in.Alice’s daughter Caroline also uses mum’s email. She wants a separate account from mum’s. Registers and gets an error stating she needs to use a different one.
Caroline uses her phone and phone number instead. Uses her phone to login. Goes through registration, no problems. Logs in.
When asked to give a recovery email, she uses mum’s again, gets an error. She gives up, uses mum’s email with a label instead
alice+caroline@example.com. Success.
As an exercise to the reader—try to model this problem first without a database. How would you model it in-memory.
Adapt it to 100 users at first and consider how you’d perform for 100 million users.
What tool database (sql or otherwise) can you use to make this problem easier
What happens if you have two of those databases?
Scenario 2
We removed the phone numbers and decided to just use verified emails. We added a verification step to emails.
Bob registers but doesn’t verify his email within 24 hours of registering. He cannot log in. Deletes verification email by mistake. He forgets.
Bob comes again the next day and registers within the 24 hour window. We know it’s Bob, but the system may betray his privacy if we keep this flow too easy. So we show an error and re-send the verification email in the background.
Second exercise to the reader.
How does the model from the previous scenario carry over to this one?
Is the solution a drop-in replacement or is there an adaptation to be made that’s non-trivial?
How would you test this flow?
I await your suggestions via emails and DMs. Rather than a solution, let’s tackle the process of distilling this domain model and invariants.

I chose an oversimplified example on purpose. As there is only one entity being made available for reconstitution, it’s tempting to say that should be our aggregate.
However, the invariant belongs to the system as a whole. The invariant does not affect anything inside the command-event handler or even the final User entity. Should you implement this—you will notice the same: there is nothing at creation time of the User or RegisteredUser entity that may be used to enforce this invariant as it is not intrinsically internal to that boundary. So is the aggregate something plural like Users? Do we skip having an aggregate at all?
That seems like an anemic model, a code smell even. We seem to be missing something…
Is the Invariant hiding from us?
Ask yourself—what is the Invariant enforcing?
“There should only ever be one email address uniquely identifying a user for login.”
Okay. Ever? As in—someone registering on Amazon with an email cannot register on your platform?
sigh, okay Denis—”There should only ever be one email address uniquely identifying a user for login in our system.”
Aha!
So let’s take a look at our system. What defines it? Is it the company logo? A server? Wider? Narrower? What context?
Perhaps an Identity Provider?
If you circle back to our two scenarios. Did you end up using the emails as Entity Identifiers or did you generate new ones?
It’s not uncommon for online services to allow you to register manually via gmail email address and then come back at a later point and login via OpenID Connect (the Login with Goggle button) and have the two access methods be merged.
But isn’t that just a Unique Constraint?

Yes—which is why this exercise is so important. We should always avoid modeling for purity when there is a technical approach that makes more sense and aligns with the business.
But this is tricky. Sometimes we mistake alignment due to vague business requirements. So here are some questions to ask to get more data on intended behavior:
Shall we de-duplicate user emails at registration?
What happens if we do it at login-time instead (ie. oldest-registered that was verified)?
Can a user change their email?
For the sake of identity is
alice@gmail.comequivalent toALICE@gmail.com? Why?For the sake of identity is
alice@gmail.comequivalent toalice+1@gmail.com? Why?
We are claiming identities because we want to have a handshake with the human owner of an email account. To verify who they are on a very abstract level.
Let’s last item on the list above is to be deduplicated as well—can you still perform that with a unique db constraint? How will you record the labels? Trim them? What happens when Alice wants to login with the label on the login form?
And you thought identity management was trivial?
It turns out—the answer to all of the above questions is… it depends.
And these questions can quickly become annoying.
It depends on how your business is using this workflow. What’s valuable to the users? What provides a smooth user experience? Are they personal or corporate accounts?
Annoying Questions without Annoying People
Focus on the objective. Ask no-oriented questions towards simplification first:
“Is it a problem if I simplify the domain by doing this?”
“Is it too much to invest more into refining this part of the domain?“
“Would a non-technical person describe this to their colleagues like this?“
“Have we normalised the model too much?“
“Is the public API supposed to include this level of jargon?“
Minimum is Clumsy—Maximum is Ridiculous
How large should the aggregate be? First of all some ground rules:
Several entities (they can be the same type)
Business Rules that define the boundary and apply only within the boundary
Large enough to avoid being chatty with the outside world
Small enough to encompass the entities
Aggregates can reference other aggregates—Often this is the solution when implementation is naturally complex
Domain Services (á la Vaughn Vernon: Implementing DDD) are often used to denote collaboration between services.
Below is a picture of my interpretation of how I saw these kinds of systems evolve naturally in startups and corporations. Domain Experts introduce the pressure on the system to solve richer and more complex problems. The context around the User boundary shifts and starts introducing new borders, new contexts—growing and splitting the entities at the same time.
This ongoing modeling can be quite difficult. But it is this on-going refactoring and remodelling that is driving DDD. The hard parts are where the value lies.

Exercises to the reader:
With the picture above—can you model a quick pseudo implementation and tests? Would you like to explore that together on a live session? Let me know!
How does your initial models for Scenarios 1 and 2 align with this view of the Registration/User flow?
If you found value in this issue of CTT—consider sharing it with your colleagues, architects, tech leads and backend professionals.