

E2E Tests Aren’t the Savior to a Dysfunctional Organization
End-to-end tests sound great on paper. Mimic how a user interacts, check every layer from the UI to the database. But here’s the kicker: they’re a money pit in maintenance and running expenses

Bonus for paid subs: don't miss the testing sushi maturity path and AI tips at the end of the article 🍣
$10,000 Bugfixes: Why Speed Matters
In 2024, the CrowdStrike bug made headlines, causing an estimated $10 billion in damages. It took days to recover, highlighting a painful truth: when bugs strike, the real cost isn’t just the damage—they’re expensive because of how long it takes to fix them.
This isn’t an isolated story. According to the 2024 DORA Report, 60% of teams deploy bugfixes that take at least a day to resolve.
Add to that the 2018 Stripe study, which found developers spend nearly 40% of their time on bugfixes, maintenance, and tech debt. Debugging is a time sink, not just a quality issue.
The money problem isn’t the presence of bugs. It’s how long it takes to fix them.
Key Takeaways
Coaching Study: 4 Steps to De-stress a startup that is stuck firefighting: Bring full capability of testing automation to all teams economically, instead of optimising test-writing alone. Optimise the feature actual work and quality rather than measuring and signalling the dysfunction
So what use are E2E Tests? Write only those that validate (ie. smoke out) high-value user flows.
Testing Sushi 🍣 Invest in tests that deliver tangible business outcomes and manage your risk of building features instead of fighting fires.
Testing Automation Maturity path & AI: Unreliable tests waste time and drain morale. Unreliable tools frustrate new hires. Unreliable teams frustrate stakeholders. It all starts with verifying product ambitions in the build & test step. Focus on automating how you are building things so that the team can learn about why the features are being requested. Only this way they’ll build an intuition for what software they should have built in the first place.
Coaching Study: 4 Steps to De-stress a startup that is stuck firefighting
A few years ago I attached myself to an engineer team to elevate their culture and train what they were lacking to get to the next level.
They were burnt out, overtaxed, and understaffed. TDD and CD were top-prio on my mind knowing it would help them long-term.
But short term it would take some time to clear enough trees off their plate so they could see anything other than burning woods for more than a week 🔥
We worked together to get their stress levels down and bring testing capabilities to any team and component that needed it.
They were stuck in startup quicksand: known bugs in production had such a long turnover time to fix that they needed to be planned and put on the roadmap, vying with political influence to get buy-in for them.
While they remained unfixed—even when the fix was undeployed and waiting— users continued to amass data corruption, analytics aggregate discrepancies and outages: which they reported on their paid support tier.
These reports were serviced by the same team that was too busy to roll out the fix. Stuck in a loop: team stuck in data remedy, operation → bugfixes and testing require political manoeuvring → long turn-over on the fix and deploy → reprocess data → no time to improve process → new bugs deployed and discovered, repeat.
Therefore we shook hands and started the improvement initiative. Time to get our hands dirty.
Step 1: Situation Analysis
Here was our initial situation analysis of potential improvement areas:
Tests written only by QA team
Tests ran only by QA team and CI automation
Long-lived feature branches
Weeks wasted on manual testing and manual tooling updates
Long onboarding time
Aggressive, estimate driven roadmaps
No product feedback loop
Main functionality overlapped with four different departments (eng, product, data, account rep)
I highlighted the main proxies for organizational dysfunction, lack of continuous delivery and proxies for lack of testing automation.
Now the work could begin.
Step 2: New principles to un-busy, un-clog & de-stress the team
Busy-ness is a symptom. One that manifests as burnout. You can’t be too busy to go to the doctor to check on your health. The linux kernel can’t be too busy to continue running your fans and manage power. When a team gets taxed to the maximum, it requires quick, decisive measures:
Zero inbox policies
Time outs on how long feature branches, tickets and stories can age
Cleanup of needless meetings from recurring agendas
Cancelling sprints that are off-target
Deleting github branches that are never going to get merged
Training the team to negotiate and hold space in tough conversations. There’s no change happening if the team is resistant, too aggressive or getting bullied all the time.
I like to get socio-technical with teams I work with as soon as possible. So this is where the rubber hits the road and the resistance and pain start kicking in. I find it helps getting this out of the way quickly so the team can learn how to act as a team.
The approaches I teach and bring to teams are not novel, they focus on core principles of a high-performing, collaborative team:
Work transparently, in the open: WIP PR’s and working on trunk hourly, daily. No 2 week old branches that can only be touched or merged by the author. The phrase “transparently, in the open” I got from Christina Entcheva, Senior Director of Engineering @GitHub (interview).
Establish shoulder-to-shoulder pairing regularly on the calendar (twice per week is a good start). The team needs to experience what it’s like rowing the boat in the same direction. They can’t do so isolated on solo tickets.
Automate manual “drudgery”. Manual testing, copy-pasting SQL queries from a giant shared clipboard doc, manual deployment procedures, written SOP documents for onboarding, reviews, version bumping, IDE setup, refreshing keys, DB updates. You name it. If a machine can do it and it’s being done by a human who isn’t enjoying it, CUT IT.
Now the team is slowly regaining lost trust between key people, learning to work together and being a bit more up front about how exhausted they really are and how much more time they need to work well, rest and finish key loops.
This took several months by the way, but the team managed to get through on a much tighter and cleaner work-loop with smaller batches. Now the team is ready to tackle the main course…
Step 3: Expand testing knowledge
This is where it gets interesting. A team that has some tests or none will usually err on the side of E2E regression tests or complex smoke tests. I’ve gone over the types in this dedicated ⛰️ Our Tech Journey episode. But I digress.
A team can only move forward confidently as fast as they can verify their previous step. As you speed up—speed in this sense meaning less time wasted—your testing cycle also has to speed up, which means End to End tests eventually become the bottleneck.
You need something faster! We’re talking nanosecond or millisecond speeds.
IDE Linter feedback
Tests running (and finishing) on KEY PRESS during code writing
All tests running in the background as you save files
Complex test scenarios able to be tested in the background before you finish writing the commit message
Full suite run in CI/CD pipeline (<15mins) as you wait for review (<1 hour)
This is the capability behind all high performing teams. Some skip the typing bits, some skip the integration-on-local-machine. But no one gets past verifying their work before creating a PR. Step 2 was all about identifying manual grunt work, Step 3 is about expanding the toolkit and knowledge needed so you don’t regress back to manual work.
This step, along with life happening in a busy product org, maintenance, new onboarding is what takes the most resilience and consistency across a significant time-span (1-3 quarters). As you see evidence of this culture taking root in at least one team, it’s time for the final step
Step 4: Testing Capability to All Teams / Components that need it
This is where the transformation happens. Or doesn’t and you go back to step 0.
Remember, the aim is not to write tests quickly. The aim is not to have zero bugs.
The aim of test-driven, continuous delivery with automation is to get the capability of rapid, confident feedback loops to all teams that need it. Now is the right time to invite leaders from your teams to emerge and drive initiatives, guilds or internal tech talks to spread the word.
Examples:
A team you rely on has a flaky SDK → Teach them how to unit and contract test their work before sharing with other teams
QA finds lots of bugs, pushing back releases constantly → Get QA into shoulder-to-shoulder coding sessions to discuss acceptance criteria for core behavior that must be caught using fast tests on the dev’s machine
Leadership requires strict estimates and deadlines on a team with a fresh member → Make the pipeline automation uniform across all teams and teach everyone to use it, then gather data from past deployments to get everyone on the same page as to what was realistically delivered in a day, in a week. Then extrapolate from there.
Leadership still won’t back down on a 3 month road map → Stand your ground during requirements gathering and negotiation, build the capability of slicing work down so that viable, small improvements can be expressed with tests and released within a day or two. Measure your delivered pace, not your organization’s dysfunction. I have a whole series of articles about planning accuracy if you’re interested in that sort dysfunction measurement.
So what use are E2E Tests?
They make great smoke tests! Don’t get me wrong. They help you find regressions that you know about to look for. But they don’t offer guarantees for quick recovery. As you saw with Crowdstrike, a slow recovery can cost you billionsEmphasis on recovery time. I’m not implying it was caused by E2E testing.
"There is a gas leak somewhere in your house. You don't really want to hear somewhere in your house. At the very least you want to know which room the gas leak is in." —Jason Gorman
The Cost of Perfectionism
Obsession with catching every edge case leads to diminishing returns. Teams that aim for “perfect” coverage miss deadlines, overcomplicate and burn out. Ask yourself…
Does this test reduce customer-facing risk?
Will it save engineering time in the long run?
Is it worth delaying a release for this test?
Building a culture that values pragmatism over perfection can save money—and sanity.
This is why I recommend a balanced approach of smoke tests and acceptance tests early on as a safety net and learning tool, in order to make unit testing gradually more approachable and cheaper. These are built predominantly with E2E tools, which doesn’t mean they are end-to-end tests.
Therefore, your teams and leaders must understand the underlying business economics involved with software testing automation.
Testing Sushi no pyramids, sorry
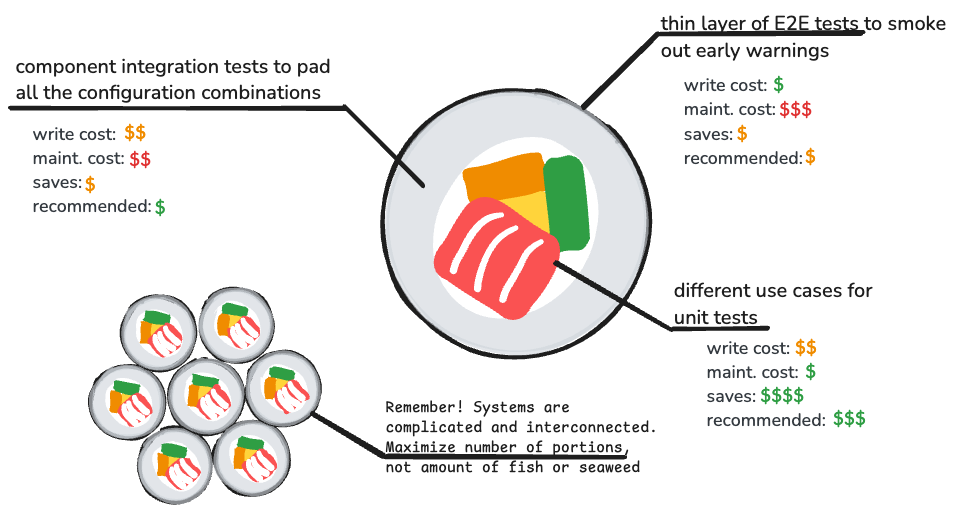
Economics—Cost Breakdown
Unit tests and integration tests can be expensive too. Explore with me a cost breakdown. A test generally comes with 4 different axes of economics:
Writing cost
Maintenance cost
Running cost
Cost saving
Writing
How much effort, time and operational overhead writing the tests takes. From setup to commit, verifying they work, along with adding new ones. There is plenty of exploration involved with making landfall to a new component and introduce any form of tests. This is where most of the initial cost goes and how most teams are tempted to base their testing strategy decisions on.
Maintenance
Changing tests, updating the testing libraries, keeping docker containers up to date, opportunity cost from refactoring, and having to rewrite tests entirely when too coupled to implementation and structure. This is what falls into maintenance costs with regards to tests. Smaller tests (few lines of code) with simple or no infrastructure dependencies are cheap to maintain. Tests that refer to code based on behavior or capability opposed to implementation (class names, function names) are much cheaper.
Running cost
Dev waiting time along with the opportunity cost this produces, CI tooling expenses, CPU time expenses. The automation costs are obvious. What’s not obvious is the manual testing cost incurred with flaky tests to verify what causes lack of determinism or random cases providing false signals.
Cost-Saving
The speed-up you gain from fixing bugs faster. Time saved from having instant test feedback as devs are typing, security feedback from your CI pipeline, time saved in manual reproduction steps being able to express a bug as a failing test and ultimately all the manual testing you don’t have to be scaling anymore.
E2E Tests are Expensive!
JUnit and its family of testing frameworks have popularised unit testing since the early 2000’s. But isolating systems of contained capability come with their own set of challenges. Challenges that you can avoid by spinning up a production-like environment and retracing a human interface.
And so End-to-end tests are born. They are called End-to-End because they require on one end the full finished product (ie. all servers, databases, components and 3rd-party interfaces) and on the other end full control over the controls of access (usually a browser or mobile device).
E2E tests are expensive because they require a lot of setup and details that are configured just right. Their risks stem from implicit defaults that the production-like environment brings with it: how many underlying components can fail and signal a false-negative? Will you ignore them if they are flaky?
The larger a system, the more permutations of capabilities it has. Will you spin up a new test and E2E environment for each one? By hand? This game is not scalable when you need strong guarantees.

Testing Automation Maturity & AI
Keep reading with a 7-day free trial
Subscribe to 🔮 Crafting Tech Teams to keep reading this post and get 7 days of free access to the full post archives.