

Plan your Releases using Event Modeling
Use your Data to Plan the part everyone cares about


A continuous delivery effort requires delivery planning. Pre-modern Agile will have you plan your features and release when your team feels like it. That works for idealistic agile teams. Teams that have a strong definition of done. Decades of experience.
But if you end up having to ask when something will be done chances are your team is not “done” and “fast” enough to rely on that.
Coming into software engineering, one may make the—albeit foolish, but— natural assumption that planning is a strategic effort. The Roadmap People!
An exercise I often do with individuals and teams during coaching is to have them plan a tactical release plan for a set of features.
The team generally has a vague idea of what done looks like, ie. what features have to be included.
However, I rarely see an effort to document how and in what order the various iterations, versions and features roll out. That is usually left till after feature-completeness and it can come with many, explosive surprises!
Make your increments visible
Why should your team care about when?
We’ll deploy it when it’s done!
How about, instead:
We’re deploying what is useful.
The wordplay isn’t a mere trick. Without a releases plan of your next two, three versions your increments are not individually useful!
So there’s naturally no need to deploy them.
But you could!
This is where most of the money is left on the table. The untapped potential for productivity that your team is looking for.
When planned incomplete features become too large, they are unwieldy for a group of people. Everyone has their own understanding of the little nuances and details.
Everyone naturally aims to synchronise this understanding upon testing and release. But at that point it’s too late!
Engineers will naturally optimise to not release needlessly when a short-term release is planned. But if the next one is too far away, the features within the increment of delivery also grow exponentially and they are not individually releasable anymore as they get grouped together. This grouping may also risk the software becoming unintentionally more coupled.

Follow the Data with Event Modeling
Small changes are easier to deploy. Think of changes as diffs, not so much PRs of full features. Here’s an example.
Magic Analytics, huddle planning
How many diffs for this magical data analytics?
Well we need to change the data ingestion… (1)
And adapt mapping and reducer models (2, 3)
Then wire it up to the interface (4)
And define how it can be visually inspected with filters (5)
Most teams will aim for 1 or 2 deploys on this. Using Event Modeling, you may diagram this to a very simple sequence (image content is not relevant).
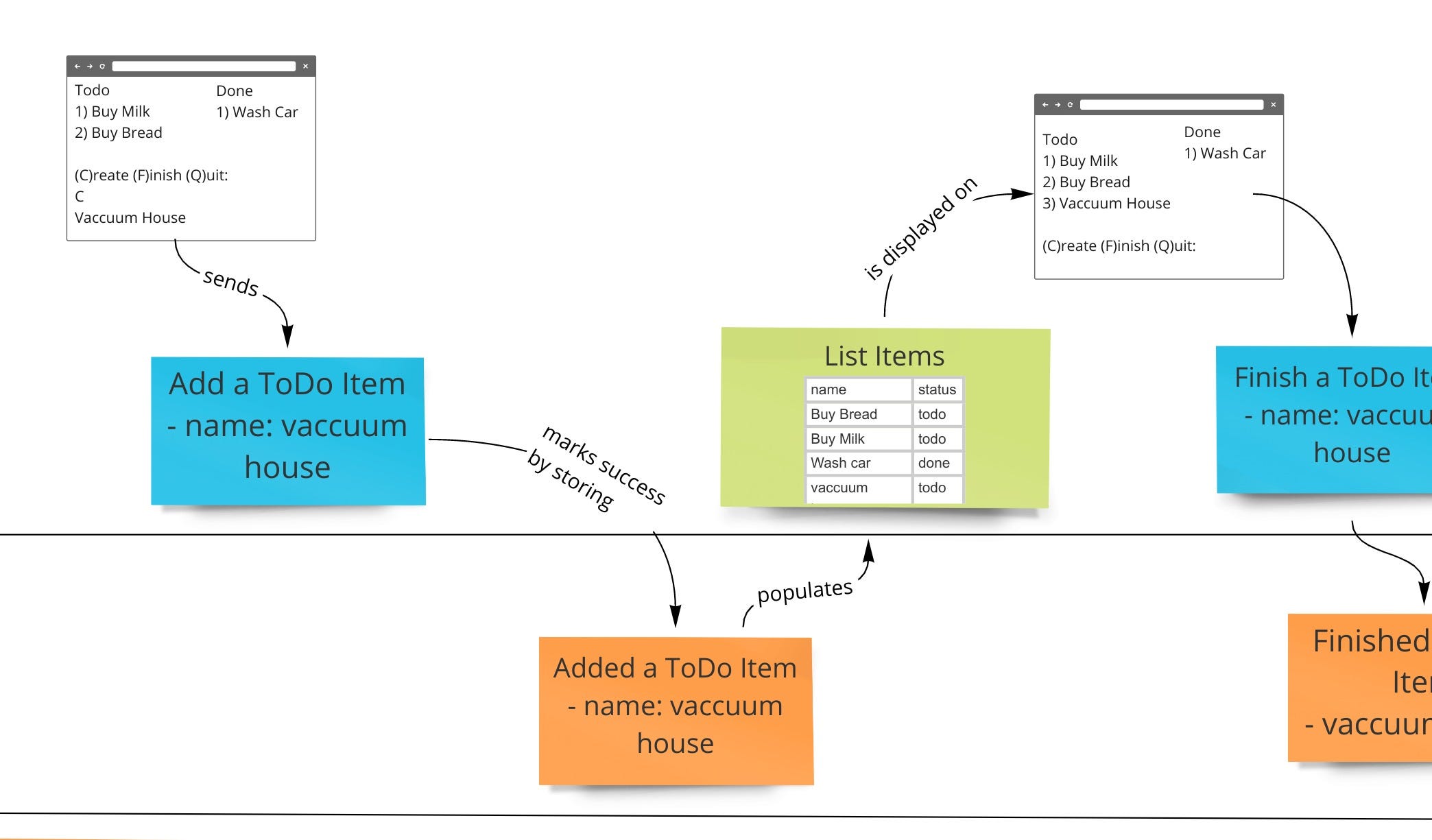
Create a Simple Event Model
UI or Automation (white) trigger commands (blue)
Commands create events (orange)
Events update Projections (green)
Projections update UI or notify Automation (white)
These 4-5 steps close a loop.
This creates a monotonically increasing data timeline. That’s how most projects are built. Especially the slow, messy ones.
But users and stakeholders do not think of products like this. They see it backwards. They see the car first (white), take it for a ride (blue), check the dashboard (green) then may take a peek under the hood to check the electronics and engine (orange).
You can release each step individually too. But they are only useful backwards. Ever tried testing a car with just its wheels?
Compare that to sitting in a prototype static cockpit. Yes, that feeling.
Teams are surprised to find out that using Event Modeling they can not only model the architecture but also the release cadence.
Magic Analytics, this time with EM
How many vertical slices for this magical data analytics?
We need to show the analytics chart on the interface. Deploy a prototype with static data. (1)
Replace the static data with a reducing projector using our current models, keeping new functionality static (2)
Add new mappers to fill the gaps for the missing data (3)
Start ingesting the data to feed the mapper (4)
Refine the UI to allow inspection with filters (5)
When I do this exercise with teams lightbulbs start appearing.
Some participants are adding the UI inspection already with static data.
Some have team topologies in mind and do 1 and 5 in parallel.
The more Team Topologies and DevOps-savvy engineers will add an intermediary infrastructure automation step to offload cognitive load for the main team between steps 2 and 4.

But it only makes sense going backwards along the Event Model.
Going forwards along the data timeline you are prone to focus activities on under-the-hood infrastructure and backend releases that no one can verify.
Balance Iteration and Re-work
On some releases you may opt to iterate on the UI, or the data model or performance. This will naturally lead to re-work and renewed, quick releases. This is a good thing! This is how all activities can and should be approached in a healthy, high-performing team.
But don’t leave it up to an unknown, short term post-launch optimisation activity.
The sky is the limit.
In fact, it’s natural to do this. Your team is naturally inclined to do this on their own. We do this every day. Ever went grocery shopping with two toddlers and you had to pick up mail? How many times did you stop for ice cream?
Bonus
Oh, if you’re wondering what the correct spelling for event modeling is - is it modelling or modeling?My auto-correct hates me!

Now you know. That’s from the Event Modeling Slack Community.