


Refactoring: Become a Code Smell Firefighter 🚒
Principles of good coding hygiene your team can easily adopt


A new format today. Below you’ll find cases of code smells. You can read a book on Refactoring or Clean Code to figure out what they are and what to do in an ideal world.
But the world is messy.
Your team, peers past- and future-coworkers all likely know what they should be done. Yet, there is something very human and pragmatic preventing us all from doing the right things at the right time.
That human element is what I’m interested in.
So today we’ll explore not only what code smells are, but also why they are so attractive and what prevents us from building better habits.
Let’s dive in!
To highlight some more complex cases I will be referring to the popular Gilded Rose Kata.
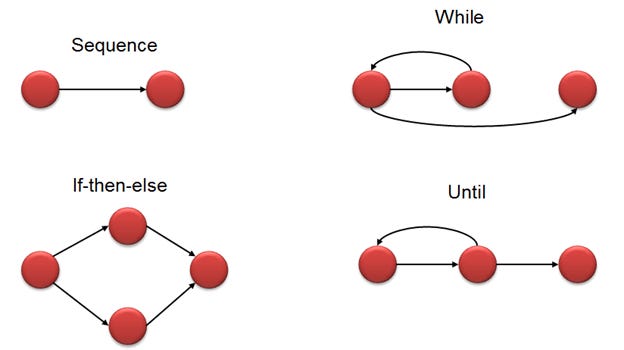
Cyclomatic Complexity
CC is easy. Following the simple diagram above, we want to minimize the nodes that contain conditional.
The formal definition for McCabe’s CC is:
CC = NumNodes - NumEdges + 2That’s all fine and well but it never made sense to me, so here’s a simplification:
CC = Number of Conditions + 1What’s a condition?
if ($a > $b) echo "This is one in PHP. +1 CC";
for (let i = 0; i < n; i++) console.log("This is another one in javascript. +1 CC");
for (let y of X) alert("Just a fancy way of doing a while/for loop. Also +1 CC");If-then-else-if is the main offender by miles, and it gets worse when you nest it. Follow the credit link in the image for some more diagrams!
What motivates us to do it badly?
Software is similar to chess. To visualise the board of possibilities engineers will approach each branch individually and then try to mix and match their outcomes, making their branched paths align beautifully. Well… in theory anyway.
In reality, it’s hard to think more than four or five steps ahead and we quickly get overwhelmed without refactoring unless we keep a solid test suite at hand.
Simply put: we write one problem at a time. Following a linear path we end up with diverging decision trees that have to be corralled back together at the return statement.
What is the benefit of doing it well?
Code within the 2-8 range is considered very healthy. A healthy codebase is what allows zen and more importantly— flow. It reduces the cognitive load for each task, for each function, for each line of code to the degree that you can start and stop with very little effort. This lends itself very well to continuous delivery.
It’s no surprise that the recent rise of the DORA and SPACE metrics are driving a popular movement (see Fast Flow Conference) that combine Team Topologies, Domain-driven Design and Continuous Delivery to spearhead the post-Agile and Scrum era towards modern software engineering.
This movement’s researchers indicate that top performing teams optimise for flow. Reduce cognitive load and have clear responsibilities for different types of team topologies.
How to improve CC
Centralise data-transformation to extracted methods
Identify your main side-effect or mutation inside the function. These are usually towards the bottom, close to the return with deep nesting. Keep those, extract or isolate the rest
Use guard block to return early.
Corral your exception handling to middleware. Handle frequent error-paths naturally without exceptions.
Separate control flow state (are we done downloading and paginating?) from your aggregate state (this class is valid when rules A and B are enforced). Extract both and keep the calling functionality in the piece that gets left over.
In imperative languages, most logic flow is either complex business validation or data state mutation. Rename classes to better fit their main behavior. A DTO that returns itself in the end and spends the first 50 lines of code validating its state is a builder or factory, not the DTO. Imperative construction is important, however. Often we want a common User object, but differentiate it based on what we built it from. Name the class from the input port and pass on a common interface instead.
Become a Never-nester
This brings us to the next code smell. The Bumpy Road. Engineers who avoid Bumpy Road like the plague are called Never Nesters.
Because they tend to avoid nesting past the 3rd logical level. The short video below highlights it very well.
The Bumpy Road code smell is called such because code ends up looking like this. It’s zoomed out on purpose to highlight the indentation snaking. Yes that’s one function!

What motivates us to nest?
Nesting gives us the illusion of logical grouping. That illusion is difficult to maintain once you get past a few levels as the possible branches from loops and if-else-then combinations overwhelm even the best engineer. We return once more to cognitive load.

Nesting at its worst combines two smells:
The important code is at the deepest level — low cohesion
The critical, complex path requires you to understand all levels up to that point — high cognitive load
Even worse, once you find out what the code is doing, it’s difficult to unravel unless you have full understanding of the entire gordian knot.
What is the benefit of never-nesting?
The immediate business impact is fewer nested levels means less moving parts.
You want a few, highly modular pieces in your system rather than hundreds of awkwardly coupled ones. Maintaining a healthy nesting limit will also force you to keep high cohesion. Separate them out before they reach a critical cyclomatic complexity.
Dependency Injection Hell
I’m sure you’ve seen this before:
public Checkout(ISettings settings, INotification notification, IServer server, IPriceCache priceCache)
{
Settings = settings;
Notification = notificartion;
Server = server;
PriceCache = priceCache;
}Along with its C#, Java and PHP-Symfony-inspired brain child:
public CheckoutImpl(ISettingsProvider settingsProvider, INotification notification, IServerProvider serverProvider, IPriceCacheProviderGetFactoryThing ipcpgft)
{
...
}… sigh …
To quote Kevlin Henney twice!:
“Don’t inject the Thing that gets the Thing! Inject the Thing that you want!”
“Injecting Dependencies is nothing more than Passing Arguments.”
How did we end up here?
The strictest form of coupling is to be dependent on a class’ constructor. Not only does it prevent us from using an interface or subclass, but also messes around the constructor arguments all over the codebase.
Dependency Injection is meant to alleviate this pressure by supplying factory lambdas and memoizing pre-constructed scoped instances at the application composition root. Sadly history dealt us a bad card here. The DI movement got hyped very quickly with the evolution of Gin and Guice in the early 2000’s due to the radical use of Java annotations to separate wiring code from tagged configuration.
However, at the time Java had neither lambdas, nor memoization along with a very statically structured standard library with no streams or inverse behavior in sight. This paved the road for DI frameworks with more code being produced for their XML and YAML service configs than the actual original construction code carried with it.
This is getting better as lambdas are being embraced in true OO fashion in the 2020’s but the relics of the past still cling hard, especially in ecosystems of JVM, C# and PHP due to the slow adoption of lambdas.
What’s the return on investment?
Limit complex DI logic to its original intent: wiring together decoupled modules that don’t know about each other. By using a DI container, you can wire their concrete construction and memoization on top of standard interfaces to be used within your application layer without leaking abstractions.
Use the least amount of code possible for construction and wiring. If it’s annotations, go for it. If it’s a few lines of code writing a factory, be my guest. But be mindful of overly complex configuration and service container hierarchies.
However, most non-library user-land code relies on its own primary implementation. Use interfaces to denote strict detail, rather than generic, speculative abstractions. But more on this next week.
Acceptance vs. Commit Tests
Let’s not argue what a unit or integration test is. Your team shouldn’t care what slice they test per se. Tests are about feedback. Fast feedback.
And in most modern applications, especially on the web we want feedbacks on two major checkpoints:
Do the changes I’m committing break anything?
Can I deploy to production?
Answers to the former are given by Commit tests. These are your quick tactical tests.
The latter is answered by Acceptance tests. These test an actual deployment artefact, usually on a real server separate from a dev’s machine (but not production).
Why is the default no-testing so popular?
Coaching teams I see this often. Very often. They know they should test. They know the tools. They have them installed. But then crunch time hits, they want the feature out ASAP. Lunch time. Still haven’t deployed. Before they know it they can hack it together just by end of day.
The moment they have a sense of confidence it works, the motivation for testing slips away…
Until there’s a bug in two days and another week slips by trying to understand how something so simple can take so much time.
This has nothing to do with their intelligence or experience. The culprit is high team cognitive load combined with a lack of awareness for testing investment.
Tests will keep you sane and thinking about fixing, breaking, refactoring smaller scope.
But it’s up to your team to make that revelation. It’s certainly an uphill battle of less experienced developers who have little testing experience, don’t really know what good testing code looks like. Cherry on top, give them an unmaintained legacy codebase without tests and it’s no-test central!
What’s the return on investment?
Tests gives you the confidence to say “Yes.” without blinking when asked Is it working?
And more importantly.
“Will it work tomorrow when we deploy?” is answered by it’s already live, just not released.
A good delivery cadence removes the need for ongoing “when will it be done?” conversations.
I don’t know about you, but to me that level of trust and confidence is worth investing into a few tests.