

The Economics of Refactoring: Tidying, Clean Code, Agile
A tale about complexity and money

Today’s Crafting Tech Teams issue is all about trade-offs. In particular those that arise of software design, refactoring, testing and common industry trends. Whether they are the holy grail or just a fad, I leave their particular interest as an exercise to the reader.
However, there is value in exploring the intuitions and trade offs of these processes. You will learn the following:
What does code cost and how much does it make in return? Code is a liability. But just how screwed are we? Why does some code produce billions and others an instant loss? How does refactoring tie into this? What is technical debt?
Why does “small” give bigger clarity? A giant ball of mud is less total lines of code than a bunch of abstractions. Or is it? What conditions are necessary for abstractions to be worth it.
The missing ingredient in clean code, architecture and TDD. “I am applying clean code, architecture and TDD but my code isn’t getting any more profitable?!” This isn’t how these concepts work. You are missing a key ingredient.

What does code cost and how much does it make in return?
I am reading the preview of
’s new book: Tidy First?. He runs a substack with the same name. You should check it out:It details the ways in which we can refactor—specifically tidy, which is a form of micro-refactoring similar to how TPP is a micro-change in behavior (Transformation Priority Premise).
What delighted me is the detail to the economics of such processes.
When is refactoring too much?
When is it necessary?
Where on the spectrum should these decisions fall for a healthy team’s process?
When should this decision be made?
Broadly speaking, Beck postulates that the cost of software is tied to the cost of big changes in a given system, for example: yours. What makes big changes more costly than necessary? Well, coupling of course. But it’s not as simple as saying, “Okay Denis— NO COUPLING. GOT IT!”
The return, unknown as it may be at the beginning of a project, is revealed over time. But let’s assume your team’s salaries are constant and the market you are targeting as well.
Thus we have two choices extremes:
A team and its codebase where cost of software~change is low
A team and its codebase where cost of software~change is high
Both teams are targeting the same outcome, but they have no fixed guarantees. The rate of revenue once launched is the same. However, the actual cash flow is determined by:
Who starts on the market sooner (by virtue of manpower)
Whose codebase is cheaper to change (~ less time-consuming)
Who is more likely to guarantee the revenue (~ quality and product iteration, ie. low defects and early feedback)
Who defers costly refactorings to a later date after revenue has been established (big ball of mud, high coupling, but expensive later)
Why does “small” give bigger clarity?
from argues in the thread above that smaller chunks of code are more cohesive. The coupling is high in a local, cohesive area and there is no coupling to units not part of this area. This creates a fully isolated—cohesive—unit, that can be treated as a whole, without needing to change the whole when shifting behavior.
But why? How small is small and is it a linear trade-of? What is single responsibility really about?
💡 Minimising the amount of responsibilities in your global namespace.
Write assembly? It may have a million lines of instructions and only 1 logical element. It is what the code does. It works, but you can’t change it without substantial effort.
The other extreme of this spectrum? A function that does nothing.
A function that does nothing has no context, no relationships, no coupling, no cohesion with anything, not even itself. It is dead code that the compiler or interpreter will optimise out of runtime existence.
Imagine having a complexity counter. Let’s call it cyclomatic complexity.
If the entire application’s number is 200, we don’t want a single file with a complexity of 200. That would be difficult to change. That would be expensive to change. We like to say in our industry that something that is difficult to change and understand is equivalent to low quality. In other words, technical debt. Legacy code.
At the same time, you don’t want a bunch of 1’s and 0’s. That will give us more functions and classes than lines of code we started with! Sure, you’ll be able to change it, but the increments are change are going to be very small and cumbersome.
Ironically, this is what most non-practitioners of Clean code think clean code represents: Abstractions upon abstractions upon abstractions.
In reality, the goal is somewhere just above that. We don’t want 2 pieces of 100 complexity either. That’s a good step if it’s refactoring, but doesn’t help us much in the overall sense. The ideal that simple design strives for is having as few pieces of low 5’s and 4’s as possible. The scale of the number isn’t accurate in this example, it’s the direction and the distance from the zero that we care about.
How would you look at your large application written in assembly language with a cyclomatic complexity of 200 if it was chunked up into 6-10 pieces? And each piece splits further into a few 2’s, 4’s, 5’s.
How much simpler would such an application be to change compared to its original form?
How much simpler would it be to test it?
How much more composable would those pieces be?
What can you say about the quality and cost of the team and their process that maintains it?
How much cheaper would it be to change such a system?
What does that cost say about the success rate of the team?
But. Yes, there is a but. This improvement in coupling quality does not come free.
In fact, you pay for refactoring the same budget as you create features from. Aha! So that’s why software design is hard!
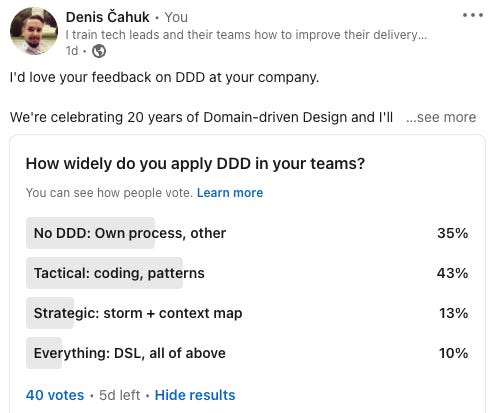
And this is where the murky areas of understanding begin. You read Clean Code but not fully. Just enough to disagree with it. You do Agile or CD but haven’t read the manifesto. You practice DDD, but only the fun bits:
The proof is in the pudding, as they say. You have to experience it fully. Practice it, not just learn it. And that’s the missing ingredient that’s hard to grok merely from books. Let’s look into it.
How deep down this rabbit hole did your team go?
The missing ingredient in clean code, architecture and TDD
We finally get to the root cause of the difficulties involved with refactoring: trade offs.
Granted, the books do mention these trade offs to some degree. However, engineers often discount the impact these trade offs have on their day-to-day. Often, any new piece of knowledge gained will be applied all-in expecting large returns then abandoned.
In isolation, without business concerns this may seem benign. But the rubber hits the road when they have to decide just how much polish, refactoring and design should go into an iteration because it always happens at the immediate expense of new features.
This isn’t to say that refactoring and abstractions are a net-negative impact. A decoupled, clean system will make future features easier to create. I have not met an engineer in 20 years who has not felt the sluggish impacts of cruft that technical debt had on their system—often caused by a lack of refactoring.
That is why seasoned tech leads and business stakeholders never want to even entertain the idea of macro-refactoring: a full rewrite.
Instead, the only course of action is do nothing or gradual amortisation: continuous micro-refactoring:
Immediate benefit. Refactoring (R) the code makes your immediate feature (rF) easier to implement and the combined cost is smaller than no refactoring (F) or refactoring later (RL)— cost(R+rF) < cost(nF) [+/- cost(RL)]
Bite the bullet. Code freeze: you do the feature. Refactoring is off the table as you vow to never touch or change this part of code again.
Tech credit. You take on a debt: deliver the cost of the feature now and gradually pay off over time, speculating that using the revenue the feature provides will be enough over time to pay off the refactoring after. The refactoring later carries a higher cost compared to having done it earlier, but you take this interest into account willingly.
Hope for the best & write-off. You complain about the feature, but don’t refactor because you are in a hurry. You give a promise to the team to create a ticket and deal with it after launch or at some time in the future. The negligent disregard of the refactoring’s cost-tracking causes these to pile-up and become more expensive, creating a bubble that can never be paid off. Such a codebase will eventually have to be abandoned or bankrupted.
The short video below highlights the main aspect of this idea in visual detail. I love CodeAesthetic, give him a follow on youtube!