


Commands, Events and Invariants
The Holy Grail of Event Sourcing

Today’s issue of Crafting Tech Teams is shining light on the Event Sourcing atomic units: Commands, Events and their Invariants. Why do we need them? What problems emerge and what solutions do we have available?

Why do we need Commands?
The Event Sourcing community separates Commands and Events. Especially the camp of developers following DDD principles. ONE OF US, ONE OF US…!
The need for this may not be obvious at first. In fact, most teams that start off with event sourced systems will often experience a symmetry in design between commands and their respective events. That is perfectly fine! But why is that so?
Imagine a world where Events could be written directly by a user to the Event Store. This would bypass all validation, not taking into account any invariants. A naive application would be forced to re-validate every single event for every single point-in-time to make sure this is prevented on the UI side.
You can no doubt imagine how many problems this creates. Worse even if it’s unfathomable!
This is where Invariants come in. An invariant is simply a business rule. You can check that out in more detail in this dedicates post…
DDD—Plan your Aggregates around Invariants

Today’s Crafting Tech Teams Issue is about Tactical Domain-driven Design Patterns. We will explore a common problem with Aggregates: when to use them—what to model them around and how what conversations to facilitate in order to discover them. I will use two scenarios to depict this from two levels of analysis–a technical one with a unique constraint and…
… but for now let’s get back to Events and Commands.
An invariant is a business rule.
Slightly more complicated than string validation.
Slightly less complicated that distributed atomic transactions
When an Event Sourced application receives a Command, that is a request to create an Event. That request has to go through the all Invariant Validations at the point-in-time of the application internal event state—usually in the context of a given aggregate or service context.
This operation is handled by a Command Processor. The processor performs a simple function: Convert Command to Event, given Invariants for Point in time.
DDD Aggregates are often used to handle transactionally complex invariants. But these may be overused. A less structured business service layer like a Checkout or a Cashier are also fine. These are all valid choices for Domain-aware Command Processors.

Creation of an Event
Once the Command has gone through the Invariant Customs check, it may be copied, converted or transformed into an Event.
Usually some data is stripped: request-specific data, sensitive user information, needless noise for XSS-prevention. Some data may be enriched—pulling in derivative data local to the aggregate to help carry the event’s context.
But possibly the most important task is the picking of an Event Type. The Command Processor has a unique opportunity to create a unique event type. This is by far the richest place in the entire Event Stream that holds domain-aware context.
Compare these example event types:
BookingCreated
BookingUpdated
vs.
BookingRequested
BookingApproved
BookingRoomChangeRequested
Choosing strong, domain-aware event types is the crowning jewel of an Event Sourced application that separates it from its Change Data Capture transitional counterpart. We discussed this in the previous articles in this series.
To summarise, commands exist to link a point-in-time of a user action to the Invariants that existed at that time and enforce them appropriately. Once enforced, validated Events get filtered through to the Event Store.
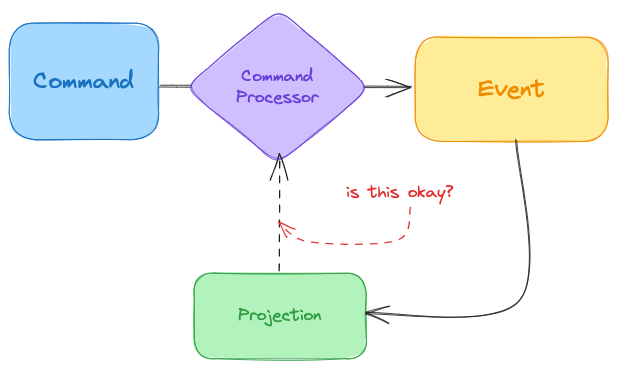
Reconstitution vs Projection
We finally get to the messy details. As you may have noticed from all command processor detail above, some invariants will require the aggregates current state. But… it’s the thing that manages changes to the event store. And the State is projected from the event store.
Professional systems design and architecture literature will quickly signal to you that these kinds of loops in data flow are usually a source of potential catastrophe.
“Recotsnihwat?!”
–10yoe Senior Rust Developer
Technically, a command processor will require local state of whatever it is operating on. It naturally gets it by replaying all prior events in its given context domain. This is of course a project. But not unlike any other. This one is special.
The Event Sourcing community calls this kind projection a Reconstitution. A reconstitution of an aggregate (or domain service data) serves only one purpose—keeping contextually appropriate join-data to perform any and all invariants. For complex Command Processors, these sometimes expand beyond the transactional boundary of a single in-process service and may be holding on eventually consistent caches of external aggregates.
Projections are Materialized Views
It should be no surprise that—as with other Batch vs. Streaming components—projections also have a batch-equivalent parallel: Materialized Views. That’s really all projections are logically and physically.
However, from an operational perspective—unlike their RDBMS equivalent that focuses on tables—projections are closer to entire Materialized Databases.
The strategy behind them is sound: keep a write-optimized event-store for the mutations to the Log and enforcing of invariants and a separate read-optimized projection for each unique use case that intimately mirrors its business use-case. This allows separate teams to flow independently.
With very clear boundaries and contracts between each event projection, UI teams are empowered to shape their schemas for the Projections they need to provide a rich User Experience.
That is the hallmark benefits of Event Sourcing and Event Modeling from an operational perspective. There are many more, including automated audits, replay capability and easy stream analytics.
That wraps up our week for Event Sourcing and Modeling while reviewing the book Designing Data-Intensive Applications by Martin Kleppmann. Did you join the challenge?
Do you know enough to start architecting appropriate event sourcing journeys within your system? What’s holding you back? I’d love to help. I’m DM friendly. Slide me a message.
Learn something new? Share it.